Learn Tutorial
本文档是为 TuGraph 的用户设计的引导程序,用户在阅读详细的文档之前,应该首先阅读该文档,对 TuGraph 的图学习运行流程有一个大致的了解,之后再阅读详细文档会更加方便。引导程序是基于 Tugraph 的一个简单的程序实例,我们将重点介绍其使用方式。
1.TuGraph 图学习模块简介
图学习是一种机器学习方法,其核心思想是利用图结构中的拓扑信息,通过顶点之间的联系及规律来进行数据分析和建模。不同于传统机器学习方法,图学习利用的数据形式为图结构,其中顶点表示数据中的实体,而边则表示实体之间的关系。通过对这些顶点和边进行特征提取和模式挖掘,可以揭示出数据中深层次的关联和规律,从而用于各种实际应用中。
这个模块是一个基于图数据库的图学习模块,主要提供了四种采样算子:Neighbor Sampling、Edge Sampling、Random Walk Sampling 和 Negative Sampling。这些算子可以用于对图中的顶点和边进行采样,从而生成训练数据。采样过程是在并行计算环境下完成的,具有高效性和可扩展性。
在采样后,我们可以使用得到的训练数据来训练一个模型。该模型可以用于各种图学习任务,比如预测、分类等。通过训练,模型可以学习到图中的顶点和边之间的关系,从而能够对新的顶点和边进行预测和分类。在实际应用中,这个模块可以被用来处理各种大规模的图数据,比如社交网络、推荐系统、生物信息学等。
2. 运行流程
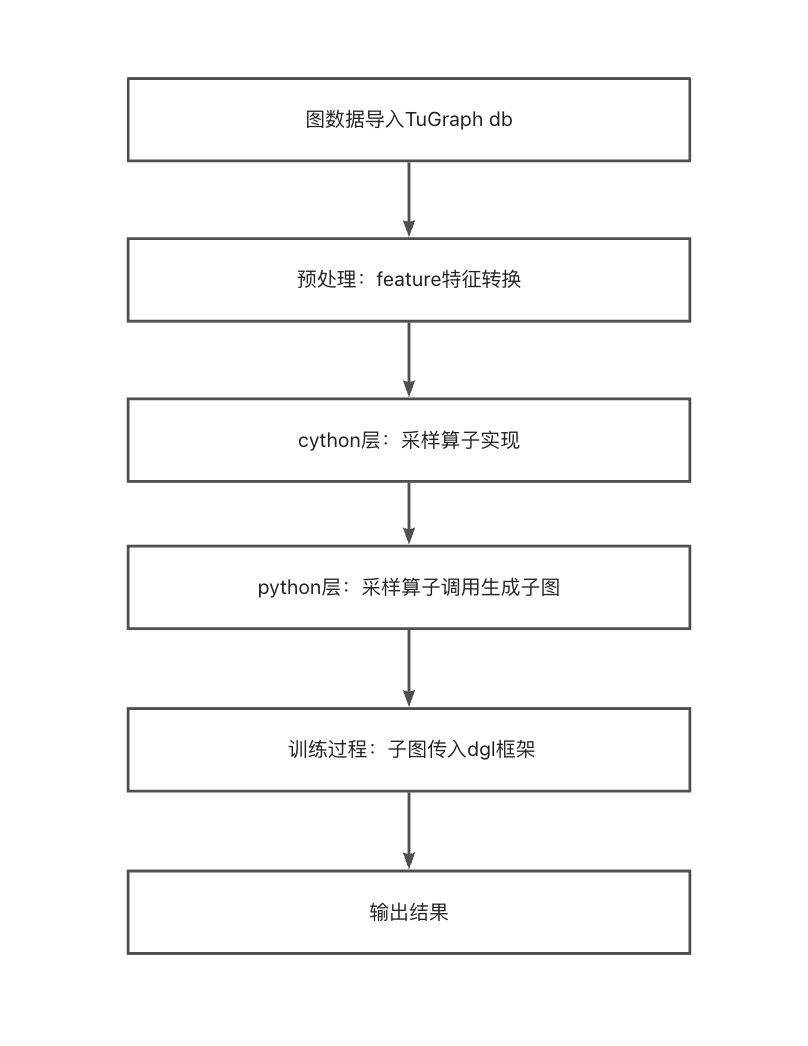
TuGraph 图学习模块将TuGraph中的图数据采样,采样后的顶点和边作为图学习的特征,进行学习训练。运行流程如下图所示:
3.TuGraph编译及数据准备
TuGraph编译请参考:编译 在build/output目录下执行:
cp -r ../../test/integration/data/ ./ && cp -r ../../learn/examples/* ./
该指令将数据集相关文件拷贝到build/output目录下。
4. 数据导入
数据导入请参考数据导入
导入过程以cora数据集为例:
在build/output目录下执行
./lgraph_import -c ./data/algo/cora.conf --dir ./coradb --overwrite 1
其中cora.conf为图schema文件,代表图数据的格式。coradb为导入后的图数据文件名称,代表图数据的存储位置。
5. feature特征转换
由于图学习中的feature特征一般表示为较长的float类型数组,TuGraph暂不支持float数组类型加载,因此可将其按照string类型导入后,转换成char*方便后续存取,具体实现可参考feature_float.cpp文件。 具体执行过程如下:
在build目录下编译导入plugin(如果TuGraph已编译可跳过):
make feature_float_embed
在build/output目录下执行
./algo/feature_float_embed ./coradb
即可进行转换。
6. 采样算子及编译
TuGraph在cython层实现了一种获取全图数据的算子及4种采样算子,具体如下:
6.1.采样算子介绍
| 采样算子 | 采样方式 |
|---|---|
| GetDB | 从数据库中获取图数据并转换成所需数据结构 |
| Neighbor Sampling | 根据给定的顶点采样其邻居顶点,得到采样子图 |
| Edge Sampling | 根据采样率采样图中的边,得到采样子图 |
| Random Walk Sampling | 根据给定的顶点,进行随机游走,得到采样子图 |
| Negative Sampling | 生成不存在边的子图。 |
6.2.编译
如果TuGraph已编译,可跳过此步骤。
在tugraph-db/build文件夹下执行
make -j2
或在tugraph-db/learn/procedures文件夹下执行
python3 setup.py build_ext -i
得到算子so后,在Python中import 即可使用。
7. 模型训练及保存
TuGraph在python层调用cython层的算子,实现图学习模型的训练。
使用 TuGraph 图学习模块使用方式介绍如下:
在build/output文件夹下执行
python3 train_full_cora.py --model_save_path ./cora_model
即可进行训练。
最终打印loss数值小于0.9,即为训练成功。至此,图模型训练完成,模型保存在cora_model文件。
8. 模��型加载
model = build_model()
model.load_state_dict(torch.load(model_save_path))
model.eval()
在使用保存的模型之前,首先需要对其进行加载。代码中,使用如上的代码对已训练模型进行加载。
加载之后,我们可以使用模型对新的顶点和边进行预测和分类。在预测时,我们可以输入一个或多个顶点,模型将输出相应的预测结果。在分类时,我们可以将整个图作为输入,模型将对图中的顶点和边进行分类,以实现任务的目标。 使用已训练的模型可以避免重新训练模型的时间和资源消耗。此外,由于模型已经学习到了图数据中顶点和边之间的关系,它可以很好地适应新的数据,从而提高预测和分类的准确度。