功能概览
此文档主要介绍 TuGraph 的主要功能和特性。
1.安装部署
1.1.部署方式
TuGraph目前提供云部署、Docker部署以及安装包部署三种部署方式,用户可根据实际情况选择适合的部署方式。
1.2.软硬件环境
TuGraph核心是由C++开发,默认使用的编译器为GCC8.4,使用c++17标准。此外,存�储过程中额外提供了Python Procedure API,该功能需要Python环境。TuGraph不需要特殊的硬件比如GPU,对RDMA、HBM等高延迟低带宽的通用硬件升级可以天然适配。
TuGraph测试过基于X86和ARM的CPU,包括Intel、AMD、Kunpeng、Hygon、飞腾等,也同时在多个操作系统上运行,包括Ubuntu、CentOS、SUSE、银河麒麟、中标麒麟、UOS的主流版本,对操作系统和CPU没有特殊的要求。
软硬件环境也包括依赖库的环境,由于TuGraph的存储层中默认的KV存储是LMDB,需要文件系统能够支持POSIX接口。在不同的环境下编译和参数配置会略有不同,比如在图存储的点边数据打包中,应和操作系统的页表大小匹配,默认为4KB,建议将系统的页表大小也设置为4KB。
2.存储层
在图数据模型上,TuGraph支持属性图模型,按照层次可以分为子图、标签(包括点标签和边标签)、属性。从存储层看,TuGraph使用使用直观的多层的树状模型,没有跨子图的标签,也没有跨标签的属性,仅保留图模型的核心逻辑。
在子图的存储上,TuGraph对多图做了数据的物理隔离,每个图对应一个LMDB的实例。多图的元数据描述信息,保存在meta的特殊的公共LMDB实例中。点边标签及其属性的存储,通过将图数据自适应地映射到KV键值对,最大程度发挥读性能。同时在KV层实现了多线程写,解决了LMDB写性能较低的劣势。主键索引和二级索引,对应LMDB中B+的表,支持基于比较的索引值增删查改。
存储层还保留了一些其他非核心功能的数据,包括权限数据、预编译的插件数据、监控数据等。
3.计算层
计算层在功能上分成三个部分,包括TP类的图事务引擎,AP类的图分析引擎和图神经网络引擎。
-
图事务引擎,主要用来处理并发的图操作,包括单点查询、邻居查询、路径遍历。图事务引擎侧重并发操作的ACID事务,确保操作逻辑不会互相干扰,主要性能指标为 QPS,即每秒完成的查询数量。
-
图分析引擎,操作类型通常为全图迭代。部分简单的分析任务(比如SPSP)可以由图事务引擎完成,复杂的分析任务均由图分析引擎完成,单个任务通常需要数秒至数小时。因此单个图分析任务要并发利用所有的硬件资源,性能指标为任务完成的总时长。
-
图神经网络引擎,通常也为全图迭代。图神经网络引擎除了基于图拓扑的操作,也需要集成一个机器学习的框架来处理向量操作,比如 PyTorch、MXNet、TenserFlow。
三个引擎的操作逻辑不尽相同,独立配置资源池。事图事务引擎基于RPC操作设置了一个线程池,每接受客户端的一个操作,从线程中取一个线程来处理,并发执行的数量等于RPC线程池的容量,通常配置为服务器的核数。图分析引擎有一个分析线程池,每个图分析任务会并发执行,即用所有的线程来执行一个任务,来加速操作的性能。TuGraph图分析操作串行执行的特性会一定程度限制用户的使用体验,并发的图分析的需求可以通过高可用部署的方式,增加机器资源来处理,或者接入外部的任务调度器,将数据传到实时调度的容器来计算。图神经网络操作在图上的操作会复用图事务引擎或图分析引擎的资源,向量的操作会起单独的资源,在机器学习框架中可以使用GPU等单独的加速硬件。
4.核心功能
4.1.查询语言
TuGraph 提供 Cypher 图查询语言,遵循OpenCypher标准。
-
支持Procedure嵌入
-
可插拔优化框架 各类优化功能
-
可扩展安全性检查框架 对于cypher进行
4.2.存储过程
当用户需要表达的查询/更新逻辑较为复杂(例如 Cypher 无法描述,或是对性能要求较高)时,相比调用多个 REST 请求并在客户端完成整个 处理流程的方式,TuGraph 提供的存储过程(Procedure)是更简洁和高效的选择。
从 3.5 版本开始,TuGraph 重新设计了新的存储过程编程范式,支持定义标准的签名和结果,支持POG编程。
TuGraph 支持 POG (Procedres on Graph Query Languages) 编程和 POG 库,其中“Graph Query Languages”包含 Cypher 以及 制定中的 ISO GQL 等图查询语言。POG 库提供在查询语言中对用户定义的存储过程的访问,打破了查询语言和存储过程之间的界限,扩展了查询 语言的使用范围。
这个文档描述了 新的 Procedure 编程范式以及 POG。
4.3.数据导入导出
尽管TuGraph本身支持数据的插入,但批量导入能够大幅提升的效率。导入的功能可以分为空库导入(离线导入)和增量导入,前者指子图是空的时候进行导入,额外的假设能够大幅提升导入的性能,在 TuGraph 中,空库导入和增量导入的吞吐率差了10 倍。在数据导出中,需要考虑导出数据的一致性,即是基于一个快照数据导出的。
TuGraph 可以通过 命令行工具lgraph_export 来对已经存放在TuGraph的图数据进行数据导出,导出格式支持CSV和JSON。
4.4.备份恢复
TUGraph的备份在功能上可分为主动/定时、离线/在线、全量/增量备份,用尽量小的存储和计算代价来完成备份。恢复功能可以恢复到最新的状态,或者历史标注的时间点,需要保证数据库是一致的状态。
4.5 数据预热
TuGraph 是基于磁盘的图数据库,仅当访问数据时,数据才会加载到内存中。因此在服务器刚开启后的一段时间内,系统性能可能会由于频繁的 IO 操作而变差。此时我们可以通过事先进行数据预热来改善这一问题。
4.6 高可用
高可用是指通过通过集群配置,做到实时多副本数据热备,在部分副本不用时,集群仍然能正常提供服务,TuGraph采用 RAFT 协议的多机热备机制,能够将 RPO 降低到接近 0 的程度。TuGraph 选择在计算层进行数据同步,同步的对象是写操作,通过 RPC 接口快速同步。TuGraph 的高可用集群采用主从模式,只有主节点处理写请求,主从节点均能处理读请求。主节点的写请求处理需要同步到多于二分之一的总节点上,多数节点写成功,该写请求才算完成。
5.客户端工具
客户端主要分为各种编程语言的SDK,OGM以及命令行工具。
客户端 SDK 主要用于二次开发,可以通过 RPC 或 REST 协议链接服务端。RPC 基于长链接有较好的性能,数据需要通过 protobuf 统一序列化。TuGraph 使用brpc,支持 Java、Python、C++ 的 rpc 客户端。REST 的协议比较宽泛,能够简单适配更加多样的环境,不同的编程语言能够简单对接。TuGraph 给出了 Python 的REST 客户端实例,命令行的交互也是用 REST 实现。
OGM(Object Graph Mapping)为面向 TuGraph 的图对象映射工具,支持将 JAVA 对象(POJO)映射到 TuGraph 中,JAVA 中的类映射为图中的节点、类中的集合映射为边、类的属性映射为图对象的属性,并提供了对应的函数操作图数据库,因此 JAVA 开发人员可以在熟悉的生态中轻松地使用 TuGraph 数据库。
命令行工具lgraph_cypher是查询客户端,可用于向 TuGraph 服务器提交 OpenCypher 请��求。lgraph_cypher客户端有两种执行模式:单命令模式和交互式模式。
6.生态工具
生态工具是企业级数据库一个非常重要的组成部分,丰富的生态工具能够大大提升图数据库的可用性,稳定性。
6.1.TuGraph DataX
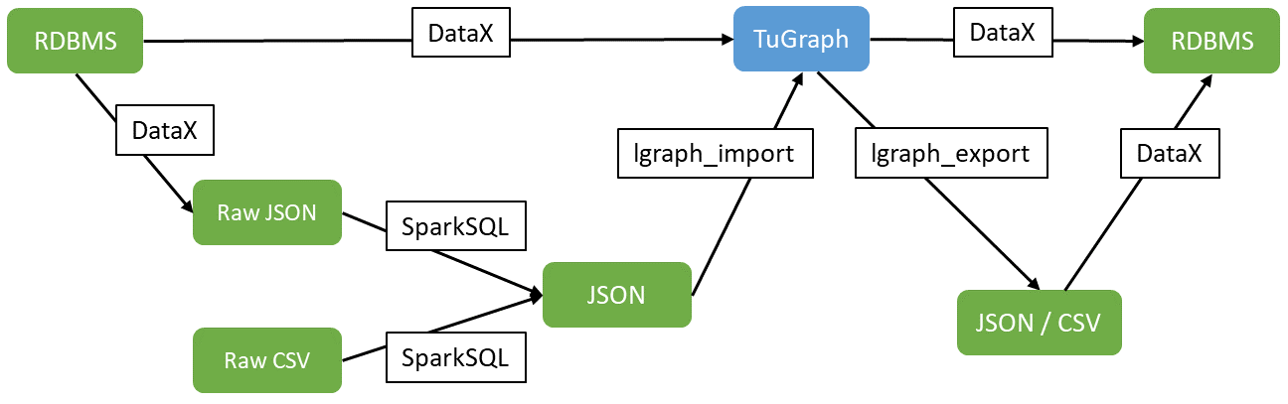
TuGraph 核心支持 CSV 和 JSON 合适的导入导出,提供空库导入和增量导入的模式。实际中会存在 MySQL、Kafka、Hive 等多数据源导入的需求,TuGraph 通过 DataX 做多数据源的对接。由于关系模型和图模型存在的差异,数据清洗的流程可以使用 SparkSQL 快速处理,TuGraph 本身仅关注 CSV 和 JSON 的简单场景导入可靠性和性能。
6.2.可视化交互
TuGraph Browser 是面向图数据库直接使用者的可视化交互界面,功能上覆盖了 TuGraph 的绝大部分能力,包括数据导入、图模型建立、数据增删查改、监控运维等操作链路。
6.3.运维监控
TuGraph 使用 Prometheus 加 Grafana 的监控框架,采用松耦合的方式。Prometheus 从 TuGraph 的监控接口获取监控信息,存储在本地时序数据库中,然后通过 Grafana 在网页端交互展示。
TuGraph 提供的监控的状态包括图数据库的状态和服务器的状态,前者包括读写负载、点边数量等数据库端的状态,后者包括内存、CPU、硬盘等服务器的实时状态。如果某些监控状态超过了预期的阈值,就需要主动告警,通常需要对接其他运维管控系统,比如群消息、邮件告警等。