名词解释
图:图用于展示不同变量之间的关系,通常包括节点(点)和边(线)两部分。节点代表一个个体或对象,边则代表它们之间的关系。图可以用来解释复杂的关系网络和信息流动,如社交网络、交通网络、物流网络等。常见的图形类��型包括有向图、无向图、树形图、地图等。
K8S:k8s是Kubernetes的简称,是一个开源的容器编排平台,提供了自动化部署、自动扩展、自动管理容器化应用程序的功能。它可以在各种云平台、物理服务器和虚拟机上运行,支持多种容器运行时,可以实现高可用性、负载均衡、自动扩容、自动修复等功能。
Graph Processing: Graph Processing是一种计算模型,用于处理图形数据结构的计算问题。图计算模型可以用于解决许多现实世界的问题,例如社交网络分析、网络流量分析、医疗诊断等,典型的系统有 Apache Giraph, Spark GraphX。
DSL: DSL是领域特定语言(Domain-Specific Language)的缩写。它是一种针对特定领域或问题的编程语言,与通用编程语言不同,DSL主要关注于解决特定领域的问题,并针对该领域的特定需求进行优化。DSL可以使得编程更加简单、高效,同时也能够提高代码的可读性和可维护性。下面的Gremlin、ISO-GQL就是DSL中的一种。
HLA: HLA 是 High level language 的缩写,与DSL不同,它使用通用语言进行编程,Geaflow目前只支持Java程序编写。它主要通过计算引擎SDK进行程序编写,执行方式是将程序整体打包交给引擎执行,对比DSL,它的执行方式更加灵活,但相对应的编程也会更加复杂。
Gremlin: Gremlin是一种图形遍历语言,用于在图形数据库中进行数据查询和操作。它是一种声明式的、基于图的编程语言,可以用于访问各种类型的图形数据库,如Apache TinkerPop、Neo4j等。它提供了一组灵活的API,可以帮助开发者在图形数据库中执行各种操作,如遍历、过滤、排序、连接、修改等。
ISO-GQL:GQL是面向属性图的标准查询语言,全称是“图形查询语言”,其为ISO/IEC国际标准数据库语言。GeaFlow不仅支持了Gremlin查询语言,而且还支持了GQL。
Window: 参考VLDB 2015 Google Dataflow Model,窗口的概念在 Geaflow 中是其数据处理逻辑中的关键要素,用于统一有界和无界的数据处理。数据流统一被看成一个个窗口数据的集合,系统处理批次的粒度也就是窗口的粒度。
Cycle: GeaFlow Scheduler调度模型中的核心数据结构,一个cycle描述为可循环执行的基本单元,包含输入,中间计算和数据交换,输出的描述。由执行计划中的vertex group生成,支持嵌套。
Event: Runtime层调度和计算交互的核心数据结构,Scheduler将一系列Event集合构建成一个State Machine,将其分发到Worker上进行计算执行。其中有些Event是可执行的,即自身具备计算语义,整个调度和计算过程为异步执行。
Graph Traversal : Graph Traversal 是指遍历图数据结构中所有节点或者部分节点的过程,在特定的顺序下访问所有节点,主要是深度优先搜索(DFS)和 广度优先搜索(BFS)。用于解决许多问题,包括查找两个节点之间的最短路径、检测图中的循环等。
Graph State: GraphState 是用来存放Geaflow的图数据或者图迭代计算过程的中间结果,提供Exactly-Once语义,并提供作业级复用的能力。GraphState 分为 Static 和 Dynamic 两种,Static 的 GraphState 将整个图看做是一个完整的,所有操作都在一张全图上进行;Dynamic 的 GraphState 认为图动态变化的,由一个个时间切片构成,所有切片构成一个完整的图,所有的操作都是在切片上进行。
Key State: KeyState 用于存放计算过程中的中间结果,通常用于流式处理,例如执行aggregation时在KeyState中记录中间聚合结果。类似GraphState,Geaflow 会将 KeyState 定期持久化,因此KeyState也提供Exactly-Once语义。KeyState根据数据结果不同可以分为KeyValueState、KeyListState、KeyMapState等。
Graph View
基本概念
GraphView是Geaflow中最核心的数据抽象,表示基于图结构的虚拟视图。它是图物理存储的一种抽象,可以表示存储和操作在多个节点上图数据。在 Geaflow中,GraphView是一等公民,用户对图的所有操作都是基于GraphView,例如将分布式点、边流作为 GraphView 增量的点/边数据集,对当前 GraphView 生成快照,用户可以基于快照图或者动态的 GraphView 触发计算。
功能描述
GraphView 主要有以下几个功能:
- 图操作,GraphView可以添加或删除�点和边数据,亦可以进行查询和在基于某个时间点切片快照。
- 图介质,GraphView可以存储到图数据库或其他存储介质(如文件系统、KV存储、宽表存储、native graph等)。
- 图切分,GraphView还支持不同图切分方法。
- 图计算,GraphView可以进行图的迭代遍历或者计算。
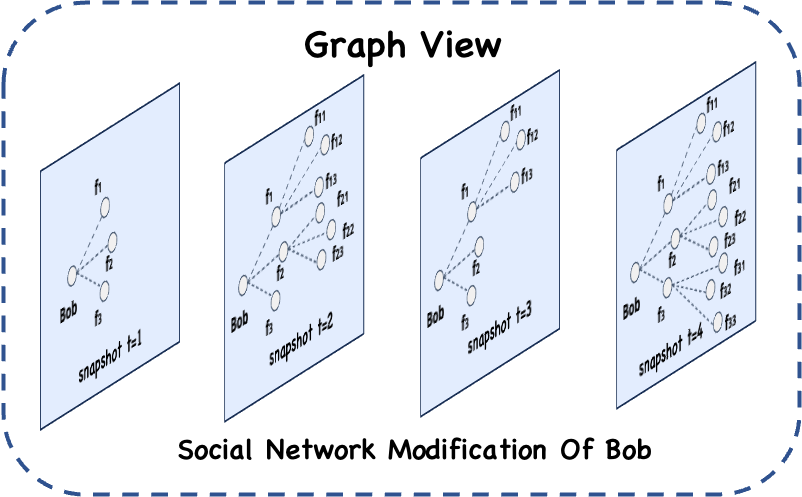
示例介绍
定义一个 Social Network 的 GraphView, 描述人际关系。
DSL 代码
CREATE GRAPH social_network (
Vertex person (
id int ID,
name varchar
),
Edge knows (
person1 int SOURCE ID,
person2 int DESTINATION ID,
weight int
)
) WITH (
storeType='rocksdb',
shardCount = 128
);
HLA 代码
//build graph view.
final String graphName = "social_network";
GraphViewDesc graphViewDesc = GraphViewBuilder
.createGraphView(graphName)
.withShardNum(128)
.withBackend(BackendType.RocksDB)
.withSchema(new GraphMetaType(IntegerType.INSTANCE, ValueVertex.class,
String.class, ValueEdge.class, Integer.class))
.build();
// bind the graphview with pipeline1
pipeline.withView(graphName, graphViewDesc);
pipeline.submit(new PipelineTask());
Stream Graph
基本概念
Streaming Graph指的是流式、动态、变化的图数据,同时在GeaFlow内部Streaming Graph也指对流式图的计算模式,它针对流式变化的图,基于图的变化进行图遍历、图匹配和图计算等操作。
基于GeaFlow框架,可以方便的针对流式变化的图动态计算。在GeaFlow中,我们抽象了Dynamic Graph和Static Graph两个核心的概念。
- Dynamic Graph 是指流式变化的图,它是图在时间轴上不断变化的切片所组成,可以方便的研究图随着时间推移的演化过程。
- Static Graph 是图在某个时间点的 Snapshot,相当于 Dynamic Graph 的一个时间切片。
功能描述
Streaming Graph 主要有以下几个功能:
- 支持流式地处理点、边数据,支持在最新的图做查询。
- 支持持续不断的更新和查询图结构,支持图结构变化带来的增量数据处理。
- 支持回溯历史,基于历史快照做查询。
- 支持图计算的计算逻辑顺序,例如基于边的时间序做计算。
示例介绍
读取点、边两个无限数据流增量构图,对于每次增量数据构图完成,会触发 traversal 计算,查找 'Bob' 的2度内的朋友随着时间推移的演进过程。
DSL 代码
set geaflow.dsl.window.size = 1;
CREATE TABLE table_knows (
personId int,
friendId int,
weight int
) WITH (
type='file',
geaflow.dsl.file.path = 'resource:///data/table_knows.txt'
);
INSERT INTO social_network.knows
SELECT personId, friendId, weight
FROM table_knows;
CREATE TABLE result (
personName varchar,
friendName varchar,
weight int
) WITH (
type='console'
);
-- Graph View Name Defined in Graph View Concept --
USE GRAPH social_network;
-- find person id 3's known persons triggered every window.
INSERT INTO result
SELECT
name,
known_name,
weight
FROM (
MATCH (a:person where a.name = 'Bob') -[e:knows]->{1, 2}(b)
RETURN a.name as name, b.name as known_name, e.weight as weight
)
HLA 代码
//build graph view.
final String graphName = "social_network";
GraphViewDesc graphViewDesc = GraphViewBuilder.createGraphView(graphName).build();
pipeline.withView(graphName, graphViewDesc);
// submit pipeLine task.
pipeline.submit(new PipelineTask() {
@Override
public void execute(IPipelineTaskContext pipelineTaskCxt) {
// build vertices streaming source.
PStreamSource<IVertex<Integer, String>> persons =
pipelineTaskCxt.buildSource(
new CollectionSource.(getVertices()), SizeTumblingWindow.of(5000));
// build edges streaming source.
PStreamSource<IEdge<Integer, Integer>> knows =
pipelineTaskCxt.buildSource(
new CollectionSource<>(getEdges()), SizeTumblingWindow.of(5000));
// build graphview by graph name.
PGraphView<Integer, String, Integer> socialNetwork =
pipelineTaskCxt.buildGraphView(graphName);
// incremental build graph view.
PIncGraphView<Integer, String, Integer> incSocialNetwor =
socialNetwork.appendGraph(vertices, edges);
// traversal by 'Bob'.
incGraphView.incrementalTraversal(new IncGraphTraversalAlgorithms(2))
.start('Bob')
.map(res -> String.format("%s,%s", res.getResponseId(), res.getResponse()))
.sink(new ConsoleSink<>());
}
});